EDIT/UPDATE: This formula, like Dean Oliver's is based on some good theory, but as I have examined it more, it is a very poor measure of defensive success. If you need a quick fix, the following explains player defense better than the formula described:
(Points Allowed On Court / Possessions Played) - (Points Allowed Off Court / Possession Off-Court)
Woo! This one took a lot of work, but I think I have all of the theoretical errors taken care of. It's very similar to Dean Oliver's box-scoreformula, but with a few important adjustments:
-'Points allowed' are assigned individually based on estimated output per possession in units of 0, 1, 2, and 3, based on Ryan Parker's bachelor essay (Rather than only assigning players Stop values that add a marginal 'DefensivePointsPerScoringPossession' per stop)
-For each possession-allowed (0,1,2, and 3), we both estimate (via blocks, defensive rebounds, turnovers, and player fouls) the effectiveness of the player's defense, but also more intuitively adjust for our unknowns (most importantly, non-block-forced-field-goal-misses). This allows us to not rely on shoving 100% of the Team Defensive Rating into the final step of the formula.
-Defensive possessions used are calculated by the marginal-used-possessions from our estimates; The base rating still lies close to 20%, but is modified only in part by blocks/stls/pf/dr.
This is for college ball, since that's where Ryan's estimates of possession-endings come from; however, the forced free throws come from my NBA-team-estimate (which is pretty lazy currently).
quick definitions for the uninformed:
DFG% = opponent's Field Goals Made / opponent's Field Goal Attempts
DOR% = opponents Offensive Rebounds / (opp. off. reb + team def. reb)
PF=player personal fouls
dFTA = Free Throw Attempts by opponents
tmBlk = (team)blocks
DR = player defensive rebounds
dFT%=opponent's Free Throws Made / opponent's Free Throw Attempts
dFGA=opp's field goal attempts
dFGM=opp's field goals made
d3PM=opp's made three pointers
Stl = player steals
Poss = team possessions, as estimated here
Let the math begin!
tMin% (team minute %)= .2 * minutes / game minutes = minutes / team minutes
(this is our basic estimate of player defensive involvement for the whole game in places where we can't assume otherwise)
PossPI (possessions played in)= Team Possessions * tMin% * 5
FMW (forced-miss-weight) = (dfg%*(1-dor%)) / (dfg%*(1-dor%)+(1-dfg%)*dor%)
(same as Dean Oliver's formula - distributes credit of missed field goal to the one guarding and the one getting the defensive rebound. Guarding man gets FMW, defensive rebounder gets 1-FMW).
eFFTA (estimated forced free-throw-attempts) = (.6033*PF^1.2132)
(This is the basic team-level estimate I got from the NBA)
FFTA (forced free-throw-attempts) = uafFTA * (dFTA/team's Sum of(uafFTA))
(This forces the prior number to make the total forced free throw attempts equal to the actual free throw attempts)
FMstops (stops from forced misses)=(Blk + .tMin%*(dFGA-dFGM-tmBLK))*FMW*(1-dOR%) + DR*(1-FMW)
(Defensive rebounds are worth 1-FMW, blocks are worth 1*FMW, and we estimate that all other DFG% can be distributed equally. My NBA-team data showed zero correlation between Blocks and Non-Blocked-Field-Goal-Misses).
0pdp (zero-points-defensive possession)
=FMstops + .27*(fFTA-fFTA*dFT%) + Stl + tMin%(dTO-tmStl)
(Gives each player full credit for their steal, and then distributes all other turnovers equally. NBA team data also seemed to show no correlation between Steals and Non-Steal-Turnovers. This, like the rest of the 'pdp' formulas is based off the possession-ending-estimates in Parker's bachelor essay.)
1pdp
=.35*FFTA - .25*fFTA*dFT%
2pdp
=.95*tMin%(dFGM-d3PM+(tmBlk-Blk)) - Blk +.36*FFTA*dFT%
This spreads out 2-pointers made between all-players, but trades out the appropriate credit for blocks. This might look a little counter-intuitive, so I might talk a bit more about this in comments or a later post. Also, we assume that each player only blocks 2-pointers.
3pdp
=tMin%*(d3PM+.02*(dFGM-d3PM)) +.03*FFTA*dFT%
dPA=1pdp + 2*2pdp + 3*3pdp
(Defensive points allowed. 1 for 1-point possessions, etc)
dPOSS=0pdp + 1pdp + 2pdp + 3pdp
(Total defensive-possessions the player is credited for ending.)
DRTG=100*(dPA/dPOSS)
dUSG%=dPOSS/dPossPI
Whew!
Here the formula is in action (from Saturday's Carolina game):


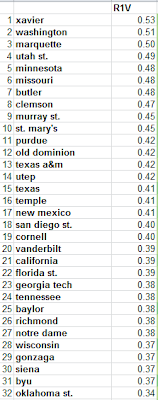


 The first three rounds are the ones that tell us the most information, l
The first three rounds are the ones that tell us the most information, l
 EDIT: I accidentally named Strickland in the paragraph on defensive plus-minus rather than Drew. Now fixed.
EDIT: I accidentally named Strickland in the paragraph on defensive plus-minus rather than Drew. Now fixed.